You don't need to learn Category Theory to be proficient at functional programming.
A little Category Theory may help you understand some concepts quicker, and it can be argued that it will make you realize how many concepts you «sorta kinda get» have deeper meanings. It is not needed by a practitioner, but it will make you an outstanding one faster, if that's your goal.
I started studying Category Theory over twenty years ago, suffering through Saunder's canonical «Categories for the Working Mathematician». I do not recommend it, even if you are a working mathematician. I felt thick as brick for a while...
I started my shift from Standard ML and Miranda towards Haskell in the early 2000's. I was advised to read Pierce's «Basic Category Theory for Computer Scientists». It made a lot more sense. I still think is too theoretical for anyone who hasn't had a strong discrete math background.
I was finally able to grasp the material after my (second) reading of Walters' «Categories and Computer Science». Not because I think it's particularly easy to follow, but because I'd read the aforementioned two: it's like reading the «Compiler's» (the «Dragon») after having studied «The Theory of Parsing, Translation, and Compiling»...
The Orange Combinator's Meetup agreed to go through Bartosz Milewski's book. I found it very entertaining: quite pragmatic, a bit «hand-wavy» at times (your Jedi tricks don't work on me), and not heavy on theory nor formalisms (not that there's anything wrong with that). Definitely not a textbook, yet able to introduce complex concepts in a somewhat familiar setting.
Each chapter has several challenges that range from writing things in Haskell, trying the same in lesser programming languages, and some equational reasoning bits.
The Orange Combinator's Meetup tries to go over the challenges in a collaborative fashion. I'm going to be adding my answers to most challenges here, after they've been discussed by the group.
Chapter 1
Implement, as best as you can, the identity function in your favorite language (or the second favorite, if your favorite language happens to be Haskell).
Perl functions receive a list of arguments and are all consumed at once (no currying). Perl functions also have a calling context, sometimes requiring a scalar value, sometimes requiring a list.
Therefore, to be as polymorphic as possible, one needs to figure out said context. That way
idover a scalar will return that scalar, butidover a list will return the list if a list is wanted.#!/usr/bin/perl sub id { @_ if wantarray; shift } print id(42), "\n"; # Scalar context print length id(69,"hello"),"\n"; # List context (length wants a list)Implement the composition function in your favorite language. It takes two functions as arguments and returns a function that is their composition.
In order for this to work, your favorite language must have functions as first-class objects: that is, you must be able to pass and return functions through other functions. This has been possible in Perl, way before other «modern and popular» languages started providing it.
Let's assume we are going to compose single-argument functions. In that case, it's straightforward:
composereceives two function references, and returns a new function reference such that it feeds its argument to the functions in sequence.#!/usr/bin/perl sub compose { my ($f,$g) = @_; sub { my $x = shift; $f->( $g->($x) ) } } sub add2 { my $n = shift; $n + 2 } sub times2 { my $n = shift; $n * 2 } my $h = compose( \&add2, \×2 ); print $h->( 20 ), "\n"; # add2(times2(20))When is a directed graph a category?
When every node has a loop to itself (identities), and when all possible paths are represented explicitly.
Chapter 2
Define a higher-order function
memoizein your favorite language. This function takes a pure functionfas an argument and returns a function that behaves almost exactly likef, except that it only calls the original function once for every argument, stores the result internally, and subsequently returns this stored result every time it's called with the same argument.I don't need to write it in Perl, because the standard library already includes the
Memoizemodule that does this in a general way. However, this is one of the standard examples of «can your language do this?» I used to show in class. Here it isHow many different functions are there from
BooltoBool? Can you implement them all?The cardinality of a type is the number of possible values, so
| Bool | = | { False, True } | = 2Now, the cardinality for a function type
a -> bis| a -> b | = |b|^|a|in our case
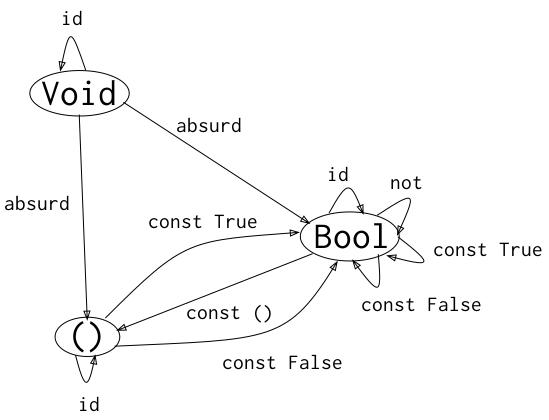
|Bool|^|Bool| = 2^2 = 4, so there are exactly four functions. They are-- f0 = id f0 :: Bool -> Bool f0 True = True f0 False = False -- f1 = not f1 :: Bool -> Bool f1 True = False f1 False = True -- f2 = const False f2 :: Bool -> Bool f2 True = False f2 False = False -- f3 = const True f3 :: Bool -> Bool f3 True = True f3 False = TrueDraw a picture of a category whose only objects are the types
Void,()(unit), andBool; with arrows corresponding to all possible functions between these types. Label the arrows with the names of the functions.Cardinalities are helpful to figure out functions
Voidis the type with no elements (empty set) having cardinality0. Therefore: there is only one function takingVoidand producinga(anything). Reason|Void -> a| = |a|^|Void| = |a|^0 = 1and the function is named
absurd. There arn't any functions producingVoidas there's no value to produce.()(unit) is the type with exactly one element having cardinality 1. Therefore, for any given typea(anything), we reason|() -> a| = |a|^|()| = |a|^1 = |a|so there are as many functions from
()toaas elements are ina. Pick any elementxina, and useconst x. We can also reason, for any given typea(anything),|a -> ()| = |()|^|a| = 1^|a| = 1there's only one function taking
aand producinv(). It ignores its argument so,const ().We already know there are four functions from
BooltoBool(those would be loops), so we only need to figure functions relating toVoidand().
These are the morphisms and the associated functions
Void -> Void --> id Void -> () --> absurd Void -> Bool --> absurd () -> () --> id () -> Bool --> const True () -> Bool --> const False Bool -> () --> const () Bool -> Bool --> id Bool -> Bool --> not Bool -> Bool --> const True Bool -> Bool --> const FalseAnd we can draw it as
Chapter 3
Considering that
Boolis a set of two valuesTrueandFalse, show that it forms two (set-theoretical) monoids with respect to, respectively, operator&&(AND) and||(OR).For the binary operator
AND.&&takes twoBooland produces aBoolas result (closure).(a && b) && c = a && (b && c)becauseANDis associative.True && x = x && True = xmakesTruethe neutral element.
For the binary operator
OR.||takes twoBooland produces aBoolas result (closure).(a || b) || c = a || (b || c)becauseORis associative.False && x = x && False = xmakesFalsethe neutral element.
Each type in Haskell can have exactly one instance for any given typeclass. That's why we need to use
newtypeto be able to have both instances simultaneously. Also, Haskell'sMonoidis preceded bySemigroupfor practical reasons.newtype All = All { getAll :: Bool } instance Semigroup All where (All False) <> _ = All False (All True) <> x = x instance Monoid All where mempty = All True newtype Any = Any { getAny :: Bool } instance Semigroup Any where (Any False) <> x = x (Any True) <> _ = Any True instance Monoid Any where mempty = Any FalseRepresent the
Boolmonoid with theANDoperator as a category. List the morphisms and their rules of composition.The category has a single object. The name or structure of the object doesn't matter: it represents «the
Boolmonoid overAND».The category has three morphisms, all of them loops:
- The identity morphism --
True. - The «
AND False» morphism --(&&False)section. - The «
AND True» morphism --(&&True)section.
The rules of composition are as follows:
- Start with the identity morphism, making
Truethe current result. - Use either «
AND False» or «AND True» computing the logical AND between the previous result and the current morphism, thus becoming the current result. - Repeat (2) for as many compositions as needed.
- The identity morphism --
Chapter 4
I refuse to code in C++
Chapter 5
Show that the terminal object is unique up to isomorphism.
Let's suppose we have two terminal objects
t1andt2. Sincet1is terminal, there is a unique morphismffromt2tot1. By the same token, sincet2is terminal, there is a unique morphismgfromt1tot2. We havef :: t2 -> t1 g :: t1 -> t2
The composition
f . gmust be a morphism fromt1tot1. Butt1is terminal so there can only be one morphism fromt1tot1and it must be the identity. Thereforef . g = id.The composition
g . fmust be a morphism fromt2tot2. Butt2is terminal so there can only be one morphism fromt2tot2and it must be the identity. Thereforeg . f = id.But
f . g = id = g . fprovesfandgare inverses of each other, thus makingt1andt2isomorphic.What is the product of two objects in a poset?
A partially ordered set (poset) consists of a set and a binary relation indicating that one element of the set «precedes» another one. It's partial because not every pair of elements needs be comparable. So, for any two elements
xandyin the set, it can bex < y,x = y,x > y, or they are incomparable.We can turn the Hasse diagram for any Poset into a category by explicitly adding the identity loops, and the transitive relations (
a < b && b < c ==> a < c).Consider two objects
aandbwithin the poset. The productpofaandbmust be an object in the poset. There must be a projection («a way to find») fromptoband fromptoc, such that for any other objectp'in the poset, there's a morphism fromp'top(that is,pis «the best» in some sense).Morphisms in the category are just the relation
<. The projections we are looking for are also morphisms.Suppose
aandbare comparable, witha < b. Takeaas their product. The identity morphism is the projection fromathe product toathe smaller element, while thea < bmorphism is the projection fromathe product tobthe larger element. Sincebcannot project toa, it follows thatais the best betweenaandb. Any othera' < awould be factored by its path toa. Hence,ais the product.Suppose
aandbare incomparable, find the largest objectpsuch thatp < aandp < b. These morphisms are projections fromptoaandb, respectively. Also, for any other objectp' < p, even though there are morphismsp' < aandp' < b, they are made up of a composition that passes throughp, makingpa factor. Hence,pis the product.Therefore, the product
pfor two objectsaandbin the poset is the largest element that precedes bothaandb.What is a coproduct of two objects in a poset?
Using duality, take
pthe smallest element that is preceded byaandb. The morphismsa < pandb < pare the required injections. Any otherp'such thatp < p', would be a worse coproduct factored by that morphism.
Chapter 6
Show the isomorphism between
Maybe aandEither () aTo show
T1andT2are isomorphic we need:- A function
t1ToT2 :: T1 -> T2. - A function
t2ToT1 :: T2 -> T1. - Show
t1ToT2 . t2ToT1 = id = t2ToT1 . t1ToT2.
These are the functions
mToE :: Maybe a -> Either () a mToE Nothing = Left () -- (R1) mToE (Just x) = Right x -- (R2) eToM :: Either () a -> Maybe a eToM (Left ()) = Nothing -- (R3) eToM (Right x) = Just x -- (R4)Now we prove using equational reasoning. Recall
(f . g) x = f (g x) -- R0(A) We need to prove
eToM . mToE = id { Eta-Abstraction: f = g => f x = g x } (eToM . mToE) x = id xso we start from the left hand side
Case A.1:
(eToM . mToE) Nothing { replace LHS R0 } eToM (mToE Nothing) { replace LHS R1 } eToM (Left ()) { replace LHS R3 } Nothing { insert identity } id NothingCase A.2:
(eToM . mToE) (Just x) { replace LHS R0 } eToM (mToE (Just x)) { replace LHS R2 } eToM (Right x) { replace LHS R4 } Just x { insert identity } id (Just x)Having shown that
∀x : (eToM . mToE) x = id xit follows
eToM . mToE = idproving (A).
(B) We need to prove
mToE . eToM = id { Eta-Abstraction: f = g => f x = g x } (mToE . eToM) x = id xso we start from the left hand side
Case B.1:
(mToE . eToM) (Left ()) { replace LHS R0 } mToE (eToM (Left ())) { replace LHS R3 } mToE Nothing { replace LHS R1 } Nothing { insert identity } id NothingCase B.2:
(mToE . eToM) (Right x) { replace LHS R0 } mToE (eToM (Right x)) { replace LHS R4 } mToE (Just x) { replace LHS R2 } Right x { insert identity } id (Right x)Having shown that
∀x : (mToE . eToM) x = id xit follows
mToE . eToM = idthus proving (B).
Proving (A) and (B) implies
mToEandeToMare their respective inverses, thus establishing the isomorphism betweenMaybe aandEither () a.- A function
Show that
a + a = 2 x aholds for types up to isomorphism.For algebraic types
a + ais the disjoint union of typeawith itself, so it can be modeled withEither a a, whereas2 x ais the product of a type with cardinality 2, such asBool, and arbitrary typea, so it can be modeled with(Bool,a).We propose the functions
sToP :: Either a a -> (Bool,a) sToP (Left x) = (False,x) -- (R1) sToP (Right x) = (True,x) -- (R2) pToS :: (Bool,a) -> Either a a pToS (False,x) = Left x -- (R3) pToS (True,x) = Right x -- (R4)Now we prove using equational reasoning. Recall
(f . g) x = f (g x) -- R0(A) We need to prove
pToS . sToP = id { Eta-Abstraction: f = g => f x = g x } (pToS . sToP) x = id xso we start from the left hand side
Case A.1:
(pToS . sToP) (Left x) { replace LHS R0 } pToS (sToP (Left x)) { replace LHS R1 } pToS (False,x) { replace LHS R3 } Left x { insert identity } id (Left x)Case A.2:
(pToS . sToP) (Right x) { replace LHS R0 } pToS (sToP (Right x)) { replace LHS R2 } pToS (True,x) { replace LHS R4 } Right x { insert identity } id (Right x)Having shown that
∀x : (pToS . sToP) x = id xit follows
pToS . sToP = idproving (A).
(B) We need to prove
sToP . pToS = id { Eta-Abstraction: f = g => f x = g x } (sToP . pToS) x = id xso we start from the left hand side
Case B.1:
(sToP . pToS) (False,x) { replace LHS R0 } sToP (pTos (False,x)) { replace LHS R3 } sToP (Left x) { replace LHS R1 } (False,x) { insert identity } id (False,x)Case B.2:
(sToP . pToS) (True,x) { replace LHS R0 } sToP (pToS (True,x)) { replace LHS R4 } sToP (Right x) { replace LHS R2 } (True,x) { insert identity } id (True,x)Having shown that
∀x :(sToP . pToS) x = id xit follows
sToP . pToS = idproving (B).
Proving (A) and (B) implies
sToPandpToSare their respective inverses, thus establishing the isomorphism betweenEiter a aand(Bool,a).
Chapter 7
Prove functor laws for the reader functor.
Recall the
Readerfunctor is nothing but a function, havinginstance Functor ((->) r) where fmap f g = f . gPreservation of Identity:
fmap id h { fmap definition for Reader } id . h { Eta-extension } (id . h) x { Composition definition } id (h x)Preservation of Composition:
fmap (g . f) h { fmap definition for Reader } (g . f) . h { Innermost composition } g . (f . h) { Innermost fmap instance } g . (fmap f h) { Outermost fmap instance } fmap g (fmap f h) { Composition definition } (fmap g . fmap f) hProve the functor laws for the list functor.
Recall the
Listfunctor defined by the bookdata List a = Nil | Cons a (List a) length :: List a -> Int length Nil = 0 length (Cons x xs) = 1 + length xs instance Functor List where fmap f Nil = Nil fmap f (Cons x xs) = Cons (f x) (fmap f xs)Preservation of Identity:
Base case:
fmap id Nil { fmap definition for List } Nil { Insert identity } id NilInductive Hypothesis:
For all lists
xshavinglength xs <= n, it is true thatfmap id xs = id xs.Inductive case:
Let
length xs = nthenlength (Cons x xs) > nfmap id (Cons x xs) { fmap definition for List } Cons (id x) (fmap id xs) { Apply identity } Cons x (fmap id xs) { Inductive Hypothesis: length xs <= n } Cons x xs { Insert identity } id (Cons x xs)Preservation of Composition:
Base case:
fmap (g . f) Nil { fmap definition for List } Nil { fmap g definition for List } fmap g Nil { fmap f definition for List } fmap g (fmap f Nil) { Composition definition } (fmap g . fmap f) NilInductive Hypothesis:
For all lists
xshavinglength xs <= n, it is true thatfmap (g . f) xs = (fmap g . fmap f) xs.Inductive case:
Let
length xs = nthenlength (Cons x xs) > nfmap (g . f) (Cons x xs) { fmap definition for List } Cons ((g . f) x) (fmap (g . f) xs) { Composition definition } Cons (g (f x)) (fmap (g . f) xs) { Inductive Hypothesis: length xs <= n } Cons (g (f x)) ((fmap g . fmap f) xs) { Composition definition } Cons (g (f x)) (fmap g (fmap f xs)) { fmap g definition for List } fmap g (Cons (f x) (fmap f xs) { fmap f definition for List } fmap g (fmap f (Cons x xs)) { Composition definition } (fmap g . fmap f) (Cons x xs)
Chapter 8
Show the data type
data Pair a b = Pair a bis aBifunctor. For additional credit implement all three methods ofBifunctorand use equational reasoning to show that these definitions are compatible with the default implementations whenever they can be applied.data Pair a b = Pair a b instance Bifunctor where bimap f g (Pair x y) = Pair (f x) (g y) first f (Pair x y) = Pair (f x) y second g (Pair x y) = Pair x (g y)Now, given
bimapprove defaultfirstandsecondworkfirst h (Pair p q) { Default implementation for first } bimap h id (Pair p q) { Provided bimap: f ~ h, g ~ id, x ~ p, y ~ q } Pair (h p) (id q) { Apply identity } Pair (h p) q second h (Pair p q) { Default implementation for second } bimap id h (Pair p q) { Provided bimap: f ~ id, g ~ h, x ~ p, y ~ q } Pair (id p) (h q) { Apply identity } Pair p (h q)Finally, given
firstandsecondprove defaultbimapworksbimap j k (Pair p q) { Default implementation for bimap: g ~ j, h ~ k } (first j . second k) (Pair p q) { Composition definition } first j ( second k (Pair p q)) { Provided second: g ~ k, x ~ p, y ~ q } first j (Pair p (k q)) { Provided first: h ~ j, x ~ p, y ~ (k q) } Pair (j p) (k q)Show the isomorphism between the standard definition of
Maybeand this desugaringtype Maybe' a = Either (Const () a) (Identity a)The following functions establish the isomorphism
mToP :: Maybe a -> Maybe' a mToP Nothing = Left (Const ()) mToP (Just x) = Right (Identity x) pToM :: Maybe' a -> Maybe a pToM (Left (Const ())) = Nothing pToM (Right (Identity x)) = Just xShow that the following data types define bifunctors in types
aandbdata K2 c a b = K2 c instance Bifunctor K2 c where bimap _ _ (K2 k) = K2 k data Fst a b = Fst a instance Bifunctor Fst where bimap f _ (Fst x) = Fst (f x) data Snd a b = Snd b instance Bifunctor Snd where bimap _ g (Snd y) = Snd (g y)
Chapter 10
Define a natural transformation from the
Maybefunctor to the list functor. Prove the naturality condition.A natural transformation is a way to «change the wrapper» without altering the contents.
mToL :: Maybe a -> [a] mToL Nothing = [] mToL (Just x) = [x]The naturality condition states that for every
ffmap f . mToL = mToL . fmap fCase 1:
(fmap f . mToL) Nothing { Composition definition } fmap f (mToL Nothing) { mToL application } fmap f [] { fmap definition for [a] } [] { Introduce mToL } mToL Nothing { Introduce fmap for Maybe } mToL (fmap f Nothing) { Abstract composition } (mToL . fmap f) NothingCase 2:
(fmap f . mToL) (Just x) { Composition definition } fmap f (mToL (Just x)) { mToL application } fmap f [x] { fmap definition for [a] } [f x] { Introduce mToL } mToL (Just (f x)) { Introduce fmap for Maybe } mToL (fmap f (Just x)) { Abstract composition } (mtol . fmap f) (Just x)Define at least two different natural transformations between
Reader ()and the list functor. How many different lists of()are there?Using the simplified defintion
newtype Reader r b = Reader (r -> b)fixing
r ~ ()we noteReaderstores functions() -> b, therefore there are as many possible natural transformations as|b|. The challenge requestsb ~ [a], thus having an infinite cardinality: we just choose any two (their usefulness is a different discussion).Two simple choices are
alpha2a :: Reader () a -> [a] alpha2a (Reader f) = [] alpha2b :: Reader () a -> [a] alpha2b (Reader f) = [f ()]The first one «ignores» the function in the
Reader, producing and empty list as there's nothing to wrap. The second one uses the function once over()wrapping its result. Additional alternatives would use this same value more than once to build a list of arbitrary length.Continue the previous exercise with
Reader BooltoMaybeUsing the simplified defintion
newtype Reader r b = Reader (r -> b)we can ignore the function in the Reader and have nothing to wrap
alpha3a :: Reader Bool a -> Maybe a alpha3a (Reader _) = Nothingor use the function in the Reader with each possible boolean value, and wrapt the result
alpha3b :: Reader Bool a -> Maybe a alpha3b (Reader f) = Just (f True) alpha3c :: Reader Bool a -> Maybe a alpha3c (Reader f) = Just (f False)